Элементарные понятия статистики
Обзор элементарных понятий статистики.
Это
введение представляет собой краткое обсуждение
элементарных понятий, лежащих в основе любой
процедуры статистического анализа данных. Мы
выбрали темы, которые иллюстрируют основные
предположения большинства статистических
методов, предназначенных для понимания
"численной природы" действительности (Nisbett,
et al., 1987). Мы сосредотачиваем основное внимание на
"функциональных" аспектах обсуждаемых
понятий, прекрасно понимая, что предлагаемое
описание является кратким и не может исчерпать
всего предмета обсуждения. Более подробную
информацию можно найти во вводных разделах и
разделах примеров руководства пользователя
системы STATISTICA, а также в учебниках по
статистике. Мы рекомендуем следующие учебники:
Kachigan (1986) и Runyon and Haber (1976); для углубленного
обсуждения элементарной теории и основных
понятий статистики см. классическую книгу Kendall and
Stuart (1979) (перевод: М.Кендалл и А.Стьюарт "Теория
распределений" (том 1), "Статистические
выводы и связи" (том 2), "Многомерный
статистический анализ" (том 3)). На русском
языке см., например, книгу: Боровиков В.П.
"Популярное введение в программу STATISTICA",
Компьютер Пресс 1998, в которой дается популярное
описание основных статистических понятий.
Что такое переменные?
Переменные - это то,
что можно измерять, контролировать или что можно
изменять в исследованиях. Переменные отличаются
многими аспектами, особенно той ролью, которую
они играют в исследованиях, шкалой измерения и
т.д.
Исследование зависимостей в
сравнении с экспериментальными исследованиями. Большинство
эмпирических исследований данных можно отнести
к одному из названных типов. В исследовании
корреляций (зависимостей, связей...) вы не влияете
(или, по крайней мере, пытаетесь не влиять) на
переменные, а только измеряете их и хотите найти
зависимости (корреляции) между некоторыми
измеренными переменными, например, между
кровяным давлением и уровнем холестерина. В
экспериментальных исследованиях, напротив, вы
варьируете некоторые переменные и измеряете
воздействия этих изменений на другие переменные.
Например, исследователь может искусственно
увеличивать кровяное давление, а затем на
определенных уровнях давления измерить уровень
холестерина. Анализ данных в экспериментальном
исследовании также приходит к вычислению
"корреляций" (зависимостей) между
переменными, а именно, между переменными, на
которые воздействуют, и переменными, на которые
влияет это воздействие. Тем не менее,
экспериментальные данные потенциально снабжают
нас более качественной информацией. Только
экспериментально можно убедительно доказать
причинную связь между переменными. Например,
если обнаружено, что всякий раз, когда изменяется
переменная A, изменяется и переменная B, то можно
сделать вывод - "переменная A оказывает влияние
на переменную B", т.е. между переменными А и В
имеется причинная зависимость. Результаты
корреляционного исследования могут быть
проинтерпретированы в каузальных (причинных)
терминах на основе некоторой теории, но сами по
себе не могут отчетливо доказать причинность.
Зависимые и независимые
переменные. Независимыми переменными
называются переменные, которые варьируются
исследователем, тогда как зависимые переменные -
это переменные, которые измеряются или
регистрируются. Может показаться, что проведение
этого различия создает путаницу в терминологии,
поскольку как говорят некоторые студенты "все
переменные зависят от чего-нибудь". Тем не
менее, однажды отчетливо проведя это различие, вы
поймете его необходимость. Термины зависимая и
независимая переменная применяются в основном в
экспериментальном исследовании, где
экспериментатор манипулирует некоторыми
переменными, и в этом смысле они
"независимы" от реакций, свойств, намерений
и т.д. присущих объектам исследования. Некоторые
другие переменные, как предполагается, должны
"зависеть" от действий экспериментатора или
от экспериментальных условий. Иными словами,
зависимость проявляется в ответной реакции
исследуемого объекта на посланное на него
воздействие. Отчасти в противоречии с данным
разграничением понятий находится использование
их в исследованиях, где вы не варьируете
независимые переменные, а только приписываете
объекты к "экспериментальным группам",
основываясь на некоторых их априорных свойствах.
Например, если в эксперименте мужчины
сравниваются с женщинами относительно числа
лейкоцитов (WCC), содержащихся в крови, то Пол можно
назвать независимой переменной, а WCC зависимой
переменной.
Шкалы измерений. Переменные
различаются также тем "насколько хорошо"
они могут быть измерены или, другими словами, как
много измеряемой информации обеспечивает шкала
их измерений. Очевидно, в каждом измерении
присутствует некоторая ошибка, определяющая
границы "количества информации", которое
можно получить в данном измерении. Другим
фактором, определяющим количество информации,
содержащейся в переменной, является тип шкалы, в
которой проведено измерение. Различают
следующие типы шкал:(a) номинальная, (b) порядковая
(ординальная), (c) интервальная (d) относительная
(шкала отношения). Соответственно, имеем четыре
типа переменных: (a) номинальная, (b) порядковая
(ординальная), (c) интервальная и (d) относительная.
- Номинальные переменные используются только для
качественной классификации. Это означает, что
данные переменные могут быть измерены только в
терминах принадлежности к некоторым,
существенно различным классам; при этом вы не
сможете определить количество или упорядочить
эти классы. Например, вы сможете сказать, что 2
индивидуума различимы в терминах переменной А
(например, индивидуумы принадлежат к разным
национальностям). Типичные примеры номинальных
переменных - пол, национальность, цвет, город и
т.д. Часто номинальные переменные называют
категориальными.
- Порядковые переменные позволяют ранжировать
(упорядочить) объекты, указав какие из них в
большей или меньшей степени обладают качеством,
выраженным данной переменной. Однако они не
позволяют сказать "на сколько больше" или
"на сколько меньше". Порядковые переменные
иногда также называют ординальными. Типичный
пример порядковой переменной -
социоэкономический статус семьи. Мы понимаем,
что верхний средний уровень выше среднего
уровня, однако сказать, что разница между ними
равна, скажем, 18% мы не сможем. Само расположение
шкал в следующем порядке: номинальная,
порядковая, интервальная является хорошим
примером порядковой шкалы.
- Интервальные переменные позволяют не только
упорядочивать объекты измерения, но и численно
выразить и сравнить различия между ними.
Например, температура, измеренная в градусах
Фаренгейта или Цельсия, образует интервальную
шкалу. Вы можете не только сказать, что
температура 40 градусов выше, чем температура 30
градусов, но и что увеличение температуры с 20 до 40
градусов вдвое больше увеличения температуры от
30 до 40 градусов.
- Относительные переменные очень похожи на
интервальные переменные. В дополнение ко всем
свойствам переменных, измеренных в интервальной
шкале, их характерной чертой является наличие
определенной точки абсолютного нуля, таким
образом, для этих переменных являются
обоснованными предложения типа: x в два раза
больше, чем y. Типичными примерами шкал отношений
являются измерения времени или пространства.
Например, температура по Кельвину образует шкалу
отношения, и вы можете не только утверждать, что
температура 200 градусов выше, чем 100 градусов, но и
что она вдвое выше. Интервальные шкалы (например,
шкала Цельсия) не обладают данным свойством
шкалы отношения. Заметим, что в большинстве
статистических процедур не делается различия
между свойствами интервальных шкал и шкал
отношения.
Связи между переменными. Независимо
от типа, две или более переменных связаны
(зависимы) между собой, если наблюдаемые значения
этих переменных распределены согласованным
образом. Другими словами, мы говорим, что
переменные зависимы, если их значения
систематическим образом согласованы друг с
другом в имеющихся у нас наблюдениях. Например,
переменные Пол и WCC (число лейкоцитов) могли бы
рассматриваться как зависимые, если бы
большинство мужчин имело высокий уровень WCC, а
большинство женщин - низкий WCC, или наоборот. Рост
связан с Весом, потому что обычно высокие
индивиды тяжелее низких; IQ (коэффициент
интеллекта) связан с Количеством ошибок в тесте,
т.к. люди высоким значением IQ делают меньше
ошибок и т.д.
Почему зависимости между
переменными являются важными. Вообще говоря,
конечная цель всякого исследования или научного
анализа состоит в нахождение связей
(зависимостей) между переменными. Философия
науки учит, что не существует иного способа
представления знания, кроме как в терминах
зависимостей между количествами или качествами,
выраженными какими-либо переменными. Таким
образом, развитие науки всегда заключается в
нахождении новых связей между переменными.
Исследование корреляций по существу состоит в
измерении таких зависимостей непосредственным
образом. Тем не менее, экспериментальное
исследование не является в этом смысле чем-то
отличным. Например, отмеченное выше
экспериментальное сравнение WCC у мужчин и женщин
может быть описано как поиск связи между
переменными: Пол и WCC. Назначение статистики
состоит в том, чтобы помочь объективно оценить
зависимости между переменными. Действительно,
все сотни описанных в данном руководстве
процедур могут быть проинтерпретированы в
терминах оценки различных типов взаимосвязей
между переменными.
Две основные черты всякой
зависимости между переменными. Можно
отметить два самых простых свойства зависимости
между переменными: (a) величина зависимости и (b)
надежность зависимости.
- Величина. Величину зависимости легче понять и
измерить, чем надежность. Например, если любой
мужчина в вашей выборке имел значение WCC выше чем
любая женщина, то вы можете сказать, что
зависимость между двумя переменными (Пол и WCC)
очень высокая. Другими словами, вы могли бы
предсказать значения одной переменной по
значениям другой.
- Надежность ("истинность"). Надежность
взаимозависимости - менее наглядное понятие, чем
величина зависимости, однако чрезвычайно важное.
Надежность зависимости непосредственно связана
с репрезентативностью определенной выборки, на
основе которой строятся выводы. Другими словами,
надежность говорит нам о том, насколько вероятно,
что зависимость, подобная найденной вами, будет
вновь обнаружена (иными словами, подтвердится) на
данных другой выборки, извлеченной из той же
самой популяции. Следует помнить, что конечной
целью почти никогда не является изучение данной
конкретной выборки; выборка представляет
интерес лишь постольку, поскольку она дает
информацию обо всей популяции. Если ваше
исследование удовлетворяет некоторым
специальным критериям (об этом будет сказано
позже), то надежность найденных зависимостей
между переменными вашей выборки можно
количественно оценить и представить с помощью
стандартной статистической меры (называемой
p-уровень или статистический уровень значимости,
подробнее см. в следующем разделе).
Что такое статистическая
значимость (p-уровень)? Статистическая
значимость результата представляет собой
оцененную меру уверенности в его
"истинности" (в смысле
"репрезентативности выборки"). Выражаясь
более технически, p-уровень (этот термин был
впервые использован в работе Brownlee, 1960) это
показатель, находящийся в убывающей зависимости
от надежности результата. Более высокий p-
уровень соответствует более низкому уровню
доверия к найденной в выборке зависимости между
переменными. Именно, p-уровень представляет собой
вероятность ошибки, связанной с
распространением наблюдаемого результата на всю
популяцию. Например, p- уровень = .05 (т.е. 1/20)
показывает, что имеется 5% вероятность, что
найденная в выборке связь между переменными
является лишь случайной особенностью данной
выборки. Иными словами, если данная зависимость в
популяции отсутствует, а вы многократно
проводили бы подобные эксперименты, то примерно
в одном из двадцати повторений эксперимента
можно было бы ожидать такой же или более сильной
зависимости между переменными. (Отметим, что это
не то же самое, что утверждать о заведомом
наличии зависимости между переменными, которая в
среднем может быть воспроизведена в 5% или 95%
случаев; когда между переменными популяции
существует зависимость, вероятность повторения
результатов исследования, показывающих наличие
этой зависимости называется статистической
мощностью плана. Подробнее об этом см. в
разделе Анализ мощности). Во
многих исследованиях p-уровень .05
рассматривается как "приемлемая граница"
уровня ошибки.
Как определить, является ли
результат действительно значимым. Не
существует никакого способа избежать произвола
при принятии решения о том, какой уровень
значимости следует действительно считать
"значимым". Выбор определенного уровня
значимости, выше которого результаты
отвергаются как ложные, является достаточно
произвольным. На практике окончательное решение
обычно зависит от того, был ли результат
предсказан априори (т.е. до проведения опыта) или
обнаружен апостериорно в результате многих
анализов и сравнений, выполненных с множеством
данных, а также на традиции, имеющейся в данной
области исследований. Обычно во многих областях
результат p 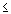 .05 является
приемлемой границей статистической значимости,
однако следует помнить, что этот уровень все еще
включает довольно большую вероятность ошибки (5%).
Результаты, значимые на уровне p .01 обычно
рассматриваются как статистически значимые, а
результаты с уровнем p .005 или p . 001
как высоко значимые. Однако следует понимать, что
данная классификация уровней значимости
достаточно произвольна и является всего лишь
неформальным соглашением, принятым на основе
практического опыта в той или иной области
исследования.
.05 является
приемлемой границей статистической значимости,
однако следует помнить, что этот уровень все еще
включает довольно большую вероятность ошибки (5%).
Результаты, значимые на уровне p .01 обычно
рассматриваются как статистически значимые, а
результаты с уровнем p .005 или p . 001
как высоко значимые. Однако следует понимать, что
данная классификация уровней значимости
достаточно произвольна и является всего лишь
неформальным соглашением, принятым на основе
практического опыта в той или иной области
исследования.
Статистическая значимость и
количество выполненных анализов. Понятно,
что чем больше число анализов вы проведете с
совокупностью собранных данных, тем большее
число значимых (на выбранном уровне) результатов
будет обнаружено чисто случайно. Например, если
вы вычисляете корреляции между 10 переменными
(имеете 45 различных коэффициентов корреляции), то
можно ожидать, что примерно два коэффициента
корреляции (один на каждые 20) чисто случайно
окажутся значимыми на уровне p .05, даже если переменные совершенно
случайны и некоррелированы в популяции.
Некоторые статистические методы, включающие
много сравнений, и, таким образом, имеющие
хороший шанс повторить такого рода ошибки,
производят специальную корректировку или
поправку на общее число сравнений. Тем не менее,
многие статистические методы (особенно простые
методы разведочного анализа данных) не
предлагают какого-либо способа решения данной
проблемы. Поэтому исследователь должен с
осторожностью оценивать надежность неожиданных
результатов.
Величина зависимости между
переменными в сравнении с надежностью
зависимости. Как было уже сказано, величина
зависимости и надежность представляют две
различные характеристики зависимостей между
переменными. Тем не менее, нельзя сказать, что они
совершенно независимы. Говоря общим языком, чем
больше величина зависимости (связи) между
переменными в выборке обычного объема, тем более
она надежна (см. следующий раздел).
Почему более сильные зависимости
между переменными являются более значимыми. Если
предполагать отсутствие зависимости между
соответствующими переменными в популяции, то
наиболее вероятно ожидать, что в исследуемой
выборке связь между этими переменными также
будет отсутствовать. Таким образом, чем более
сильная зависимость обнаружена в выборке, тем
менее вероятно, что этой зависимости нет в
популяции, из которой она извлечена. Как вы
видите, величина зависимости и значимость тесно
связаны между собой, и можно было бы попытаться
вывести значимость из величины зависимости и
наоборот. Однако указанная связь между
зависимостью и значимостью имеет место только
при фиксированном объеме выборки, поскольку при
различных объемах выборки одна и та же
зависимость может оказаться как высоко значимой,
так и незначимой вовсе (см. следующий раздел)
Почему объем выборки влияет на
значимость зависимости. Если наблюдений
мало, то соответственно имеется мало возможных
комбинаций значений этих переменных и таким
образом, вероятность случайного обнаружения
комбинации значений, показывающих сильную
зависимость, относительно велика. Рассмотрим
следующий пример. Если вы исследуете зависимость
двух переменных (Пол: мужчина/женщина и WCC:
высокий/низкий) и имеете только 4 субъекта в
выборке (2 мужчины и 2 женщины), то вероятность
того, что чисто случайно вы найдете 100%
зависимость между двумя переменными равна 1/8.
Более точно, вероятность того, что оба мужчины
имеют высокий WCC, а обе женщины - низкий WCC, или
наоборот, - равна 1/8. Теперь рассмотрим
вероятность подобного совпадения для 100
субъектов; легко видеть, что эта вероятность
равна практически нулю. Рассмотрим более общий
пример. Представим популяцию, в которой среднее
значение WCC мужчин и женщин одно и тоже. Если вы
будете повторять эксперимент, состоящий в
извлечении пары случайных выборок (одна выборка -
мужчины, другая выборка - женщины), а затем
вычислите разности выборочных средних WCC для
каждой пары выборок, то в большинстве
экспериментов результат будет близок к 0. Однако
время от времени, будут встречаться пары выборок,
в которых различие между средним количеством
лейкоцитов у мужчин и женщин будет существенно
отличаться от 0. Как часто это будет происходить?
Очевидно, чем меньше объем выборки в каждом
эксперименте, тем более вероятно появление таких
ложных результатов, которые показывают
существование зависимости между полом и WCC в
данных, полученных из популяции, где такая
зависимость на самом деле отсутствует.
Пример: "отношение числа
новорожденных мальчиков к числу новорожденных
девочек" Рассмотрим следующий пример,
заимствованный из Nisbett, et al., 1987. Имеются 2
больницы. Предположим, что в первой из них
ежедневно рождается 120 детей, во второй только 12.
В среднем отношение числа мальчиков, рождающихся
в каждой больнице, к числу девочек 50/50. Однажды
девочек родилось вдвое больше, чем мальчиков.
Спрашивается, для какой больницы данное событие
более вероятно? Ответ очевиден для статистика,
однако, он не столь очевиден неискушенному.
Конечно, такое событие гораздо более вероятно
для маленькой больницы. Объяснение этого факта
состоит в том, что вероятность случайного
отклонения (от среднего) возрастает с
уменьшением объема выборки.
Почему слабые связи могут быть
значимо доказаны только на больших выборках. Пример
из предыдущего раздела показывает, что если
связь между переменными "объективно" слабая
(т.е. свойства выборки близки к свойствам
популяции), то не существует иного способа
проверить такую зависимость кроме как
исследовать выборку достаточно большого объема.
Даже если выборка, находящаяся в вашем
распоряжении, совершенно репрезентативна,
эффект не будет статистически значимым, если
выборка мала. Аналогично, если зависимость
"объективно" (в популяции) очень сильная,
тогда она может быть обнаружена с высокой
степенью значимости даже на очень маленькой
выборке. Рассмотрим пример. Представьте, что вы
бросаете монету. Если монета слегка
несимметрична, и при подбрасывании орел выпадает
чаще решки (например, в 60% подбрасываний выпадает
орел, а в 40% решка), то 10 подбрасываний монеты было
бы не достаточно, чтобы убедить кого бы то ни
было, что монета асимметрична, даже если был бы
получен, казалось, совершенно репрезентативный
результат: 6 орлов и 4 решки. Не следует ли отсюда,
что 10 подбрасываний вообще не могут доказать
что-либо? Нет, не следует, потому что если эффект,
в принципе, очень сильный, то 10 подбрасываний
может оказаться вполне достаточно для его
доказательства. Представьте, что монета
настолько несимметрична, что всякий раз, когда вы
ее бросаете, выпадает орел. Если вы бросаете
такую монету 10 раз, и всякий раз выпадает орел,
большинство людей сочтут это убедительным
доказательством того, что с монетой что-то не то.
Другими словами, это послужило бы убедительным
доказательством того, что в популяции, состоящей
из бесконечного числа подбрасываний этой монеты
орел будет встречаться чаще, чем решка. В итоге
этих рассуждений мы приходим к выводу: если
зависимость сильная, она может быть обнаружена с
высоким уровнем значимости даже на малой
выборке.
Можно ли отсутствие связей
рассматривать как значимый результат? Чем
слабее зависимость между переменными, тем
большего объема требуется выборка, чтобы значимо
ее обнаружить. Представьте, как много бросков
монеты необходимо сделать, чтобы доказать, что
отклонение от равной вероятности выпадения орла
и решки составляет только .000001%! Необходимый
минимальный размер выборки возрастает, когда
степень эффекта, который нужно доказать, убывает.
Когда эффект близок к 0, необходимый объем
выборки для его отчетливого доказательства
приближается к бесконечности. Другими словами,
если зависимость между переменными почти
отсутствует, объем выборки, необходимый для
значимого обнаружения зависимости, почти равен
объему всей популяции, который предполагается
бесконечным. Статистическая значимость
представляет вероятность того, что подобный
результат был бы получен при проверке всей
популяции в целом. Таким образом, все, что
получено после тестирования всей популяции было
бы, по определению, значимым на наивысшем,
возможном уровне и это относится ко всем
результатам типа "нет зависимости".
Как измерить величину
зависимости между переменными. Статистиками
разработано много различных мер взаимосвязи
между переменными. Выбор определенной меры в
конкретном исследовании зависит от числа
переменных, используемых шкал измерения, природы
зависимостей и т.д. Большинство этих мер, тем не
менее, подчиняются общему принципу: они пытаются
оценить наблюдаемую зависимость, сравнивая ее с
"максимальной мыслимой зависимостью" между
рассматриваемыми переменными. Говоря
технически, обычный способ выполнить такие
оценки заключается в том, чтобы посмотреть как
варьируются значения переменных и затем
подсчитать, какую часть всей имеющейся вариации
можно объяснить наличием "общей"
("совместной") вариации двух (или более)
переменных. Говоря менее техническим языком, вы
сравниваете то "что есть общего в этих
переменных", с тем "что потенциально было бы
у них общего, если бы переменные были абсолютно
зависимы". Рассмотрим простой пример. Пусть в
вашей выборке, средний показатель (число
лейкоцитов) WCC равен 100 для мужчин и 102 для женщин.
Следовательно, вы могли бы сказать, что
отклонение каждого индивидуального значения от
общего среднего (101) содержит компоненту
связанную с полом субъекта и средняя величина ее
равна 1. Это значение, таким образом, представляет
некоторую меру связи между переменными Пол и WCC.
Конечно, это очень бедная мера зависимости, так
как она не дает никакой информации о том,
насколько велика эта связь, скажем относительно
общего изменения значений WCC. Рассмотрим крайние
возможности:
- Если все значения WCC у мужчин были бы точно равны
100, а у женщин 102, то все отклонения значений от
общего среднего в выборке всецело объяснялись бы
полом индивидуума. Поэтому вы могли бы сказать,
что пол абсолютно коррелирован (связан) с WCC,
иными словами, 100% наблюдаемых различий между
субъектами в значениях WCC объясняются полом
субъектов.
- Если же значения WCC лежат в пределах 0-1000, то та же
разность (2) между средними значениями WCC мужчин и
женщин, обнаруженная в эксперименте, составляла
бы столь малую долю общей вариации, что
полученное различие (2) считалось бы пренебрежимо
малым. Рассмотрение еще одного субъекта могло бы
изменить разность или даже изменить ее знак.
Поэтому всякая хорошая мера зависимости должна
принимать во внимание полную изменчивость
индивидуальных значений в выборке и оценивать
зависимость по тому, насколько эта изменчивость
объясняется изучаемой зависимостью.
Общая конструкция большинства
статистических критериев. Так как конечная
цель большинства статистических критериев
(тестов) состоит в оценивании зависимости между
переменными, большинство статистических тестов
следуют общему принципу, объясненному в
предыдущем разделе. Говоря техническим языком,
эти тесты представляют собой отношение
изменчивости, общей для рассматриваемых
переменных, к полной изменчивости. Например,
такой тест может представлять собой отношение
той части изменчивости WCC, которая определяется
полом, к полной изменчивости WCC (вычисленной для
объединенной выборки мужчин и женщин). Это
отношение обычно называется отношением
объясненной вариации к полной вариации. В
статистике термин объясненная вариация не
обязательно означает, что вы даете ей
"теоретическое объяснение". Он используется
только для обозначения общей вариации
рассматриваемых переменных, иными словами, для
указания на то, что часть вариации одной
переменной "объясняется" определенными
значениями другой переменной и наоборот.
Как вычисляется уровень
статистической значимости. Предположим, вы
уже вычислили меру зависимости между двумя
переменными (как объяснялось выше). Следующий
вопрос, стоящий перед вами: "насколько значима
эта зависимость?" Например, является ли 40%
объясненной дисперсии между двумя переменными
достаточным, чтобы считать зависимость значимой?
Ответ: "в зависимости от обстоятельств".
Именно, значимость зависит в основном от объема
выборки. Как уже объяснялось, в очень больших
выборках даже очень слабые зависимости между
переменными будут значимыми, в то время как в
малых выборках даже очень сильные зависимости не
являются надежными. Таким образом, для того чтобы
определить уровень статистической значимости,
вам нужна функция, которая представляла бы
зависимость между "величиной" и
"значимостью" зависимости между
переменными для каждого объема выборки. Данная
функция указала бы вам точно "насколько
вероятно получить зависимость данной величины
(или больше) в выборке данного объема, в
предположении, что в популяции такой зависимости
нет". Другими словами, эта функция давала бы
уровень значимости (p -уровень), и, следовательно,
вероятность ошибочно отклонить предположение об
отсутствии данной зависимости в популяции. Эта
"альтернативная" гипотеза (состоящая в том,
что нет зависимости в популяции) обычно
называется нулевой гипотезой. Было бы идеально,
если бы функция, вычисляющая вероятность ошибки,
была линейной и имела только различные наклоны
для разных объемов выборки. К сожалению, эта
функция существенно более сложная и не всегда
точно одна и та же. Тем не менее, в большинстве
случаев ее форма известна, и ее можно
использовать для определения уровней значимости
при исследовании выборок заданного размера.
Большинство этих функций связано с очень важным
классом распределений, называемым нормальным.
Почему важно Нормальное
распределение. Нормальное распределение
важно по многим причинам. В большинстве случаев
оно является хорошим приближением функций,
определенных в предыдущем разделе (более
подробное описание см. в разделе Все ли
статистики критериев нормально распределены?).
Распределение многих статистик является
нормальным или может быть получено из нормальных
с помощью некоторых преобразований. Рассуждая
философски, можно сказать, что нормальное
распределение представляет собой одну из
эмпирически проверенных истин относительно
общей природы действительности и его положение
может рассматриваться как один из
фундаментальных законов природы. Точная форма
нормального распределения (характерная
"колоколообразная кривая") определяется
только двумя параметрами: средним и стандартным
отклонением.
Характерное свойство нормального
распределения состоит в том, что 68% всех его
наблюдений лежат в диапазоне ±1 стандартное
отклонение от среднего, а диапазон ±2 стандартных
отклонения содержит 95% значений. Другими словами,
при нормальном распределении, стандартизованные
наблюдения, меньшие -2 или большие +2, имеют
относительную частоту менее 5%
(Стандартизованное наблюдение означает, что из
исходного значения вычтено среднее и результат
поделен на стандартное отклонение (корень из
дисперсии)). Если у вас имеется доступ к пакету STATISTICA,
Вы можете вычислить точные значения
вероятностей, связанных с различными значениями
нормального распределения, используя
Вероятностный калькулятор; например, если задать
z-значение (т.е. значение случайной величины,
имеющей стандартное нормальное распределение)
равным 4, соответствующий вероятностный уровень,
вычисленный STATISTICA будет меньше .0001, поскольку
при нормальном распределении практически все
наблюдения (т.е. более 99.99%) попадут в диапазон ±4
стандартных отклонения.
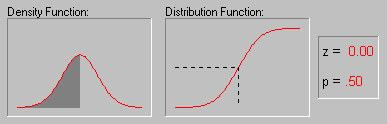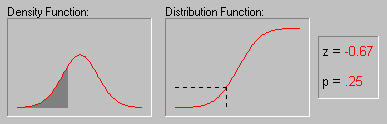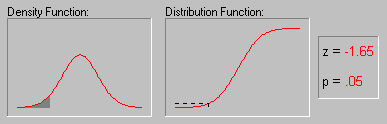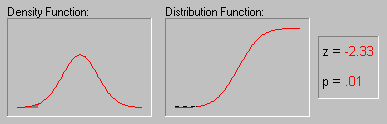
Иллюстрация того, как нормальное
распределение используется в статистических
рассуждениях (индукция). Напомним пример,
обсуждавшийся выше, когда пары выборок мужчин и
женщин выбирались из совокупности, в которой
среднее значение WCC для мужчин и женщин было в
точности одно и то же. Хотя наиболее вероятный
результат таких экспериментов (одна пара выборок
на эксперимент) состоит в том, что разность между
средними WCC для мужчин и женщин для каждой пары
близка к 0, время от время появляются пары
выборок, в которых эта разность существенно
отличается от 0. Как часто это происходит? Если
объем выборок достаточно большой, то разности
"нормально распределены" и зная форму
нормальной кривой, вы можете точно рассчитать
вероятность случайного получения результатов,
представляющих различные уровни отклонения
среднего от 0 - значения гипотетического для всей
популяции. Если вычисленная вероятность
настолько мала, что удовлетворяет принятому
заранее уровню значимости, то можно сделать лишь
один вывод: ваш результат лучше описывает
свойства популяции, чем "нулевая гипотеза".
Следует помнить, что нулевая гипотеза
рассматривается только по техническим
соображениям как начальная точка, с которой
сопоставляются эмпирические результаты.
Отметим, что все это рассуждение основано на
предположении о нормальности распределения этих
повторных выборок (т.е. нормальности выборочного
распределения). Это предположение обсуждается в
следующем разделе.
Все ли статистики критериев
нормально распределены? Не все, но
большинство из них либо имеют нормальное
распределение, либо имеют распределение,
связанное с нормальным и вычисляемое на основе нормального,
такое как t, F или хи-квадрат. Обычно
эти критериальные статистики требуют, чтобы
анализируемые переменные сами были нормально
распределены в совокупности. Многие наблюдаемые
переменные действительно нормально
распределены, что является еще одним аргументом
в пользу того, что нормальное распределение
представляет "фундаментальный закон".
Проблема может возникнуть, когда пытаются
применить тесты, основанные на предположении
нормальности, к данным, не являющимся
нормальными (смотри критерии нормальности в
разделах Непараметрическая
статистика и распределения или Дисперсионный анализ). В этих
случаях вы можете выбрать одно из двух. Во-первых,
вы можете использовать альтернативные
"непараметрические" тесты (так называемые
"свободно распределенные критерии", см.
раздел Непараметрическая статистика и
распределения). Однако это часто неудобно, потому
что обычно эти критерии имеют меньшую мощность и
обладают меньшей гибкостью. Как альтернативу, во
многих случаях вы можете все же использовать
тесты, основанные на предположении нормальности,
если уверены, что объем выборки достаточно велик.
Последняя возможность основана на чрезвычайно
важном принципе, позволяющем понять
популярность тестов, основанных на нормальности.
А именно, при возрастании объема выборки, форма
выборочного распределения (т.е. распределение
выборочной статистики критерия , этот термин был
впервые использован в работе Фишера, Fisher 1928a)
приближается к нормальной, даже если
распределение исследуемых переменных не
является нормальным. Этот принцип
иллюстрируется следующим анимационным роликом,
показывающим последовательность выборочных
распределений (полученных для
последовательности выборок возрастающего
размера: 2, 5, 10, 15 и 30), соответствующих переменным
с явно выраженным отклонением от нормальности,
т.е. имеющих заметную асимметричность
распределения.
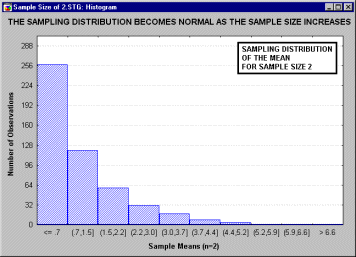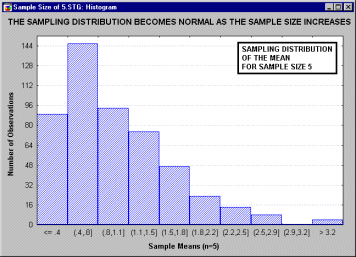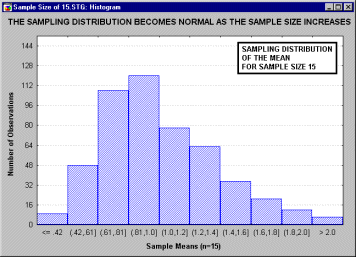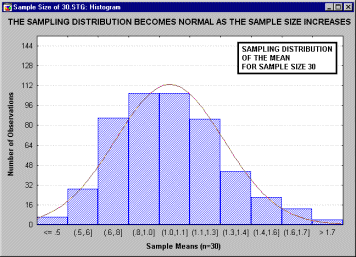
Однако по мере увеличения размера выборки,
используемой для получения распределения
выборочного среднего, это распределение
приближается к нормальному. Отметим, что при
размере выборки n=30, выборочное распределение
"почти" нормально (см. на близость линии
подгонки). Этот принцип называется центральной
предельной теоремой (впервые этот термин был
использован в работе Polya, 1920; по-немецки "Zentraler
Grenzwertsatz").
Как узнать последствия нарушений
предположений нормальности? Хотя многие
утверждения других разделов Элементарных
понятий статистики можно доказать
математически, некоторые из них не имеют
теоретического обоснования и могут быть
продемонстрированы только эмпирически, с
помощью так называемых экспериментов Moнте-Кaрло.
В этих экспериментах большое число выборок
генерируется на компьютере, а результаты
полученные из этих выборок, анализируются с
помощью различных тестов. Этим способом можно
эмпирически оценить тип и величину ошибок или
смещений, которые вы получаете, когда нарушаются
определенные теоретические предположения
тестов, используемых вами. Исследования с
помощью методов Монте- Карло интенсивно
использовались для того, чтобы оценить,
насколько тесты, основанные на предположении
нормальности, чувствительны к различным
нарушениям предположений нормальности. Общий
вывод этих исследований состоит в том, что
последствия нарушения предположения
нормальности менее фатальны, чем первоначально
предполагалось. Хотя эти выводы не означают, что
предположения нормальности можно игнорировать,
они увеличили общую популярность тестов,
основанных на нормальном распределении.

(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.