Равномерное распределение. Дискретное равномерное распределение (этот термин был впервые использован Успенским в 1937 г.) сосредоточено в нескольких точках, которым приписывает равные вероятности:
f(x) = 1/N x = 1, 2, ..., N
Непрерывное равномерное распределение сосредоточено на интервале [a, b] и имеет следующую функцию плотности:
f(x) = 1/(b-a) a < x < b
где
a - верхняя граница
интервала, из которого выбираются точки
b - нижняя граница интервала,
из которого выбираются точки
Радиальные
базисные функции. Вид нейронной
сети, имеющий промежуточный
слой из радиальных элементов и выходной слой
из линейных элементов. Сети
этого типа довольно компактны и быстро
обучаются. Предложены в работах Broomhead and Lowe (1988) и
Moody and Darkin (1989), описаны в большинстве учебников по нейронным сетям (например,
Bishop, 1995; Haykin, 1994). См. раздел Neural
Networks.
Разведочный анализ данных (РАД). В отличие от традиционной проверки гипотез, предназначенной для проверки априорных предположений, касающихся связей между переменными (например, такого рода: "Имеется положительная корреляция между возрастом человека и его/ее предрасположенностью к риску"), разведочных анализ данных (РАД) применяется для нахождения систематических связей между переменными в ситуациях, когда отсутствуют (или имеются недостаточные) априорные представления о природе этих связей. Как правило, при разведочном анализе учитывается и сравнивается большое число переменных, при этом для поиска закономерностей используются самые разные методы.
Дополнительную информацию см. в разделе Разведочный анализ данных.
Разность
(в анализе временных рядов). В данном
преобразовании временного ряда, ряд будет
преобразован как: X=X-X(лаг). После взятия разности
модифицированный ряд будет иметь длину N-лаг (где
N - длина исходного ряда).
Разрешение.
План разрешения R - это такой план, в
котором нет взаимодействий
порядка l, смешивающихся с любыми другими
взаимодействиями порядка меньше R - l. Например, в
плане с разрешением R, равным 5, нет
взаимодействий порядка l = 2, которые смешиваются
с любыми другими взаимодействиями порядка
меньше, чем R - l = 3; таким образом, главные эффекты
в этом плане не смешиваются друг с другом,
главные эффекты не смешиваются с
взаимодействиями порядка 2, а взаимодействия
порядка 2 не смешиваются друг с другом. Для
обсуждения роли разрешения в планировании
эксперимента см. 2**(k-p) дробные
факторные планы и Поиск
лучшего 2**(k-p) дробного факторного плана.
Распределение
Вейбулла. Распределение Вейбулла (Weibull, 1939
г., 1951 г.; см. также Lieblein, 1955 г.) имеет следующую
функцию плотности (для положительных параметров b,
c и ![]() ):
):
f(x) = c/b*[(x-![]() )/b]c-1
* e^{-[(x-
)/b]c-1
* e^{-[(x-![]() )/b]c}
)/b]c}
![]() < x, b > 0, c
> 0
< x, b > 0, c
> 0
где
b - параметр масштаба
распределения
c - параметр (формы)
распределения
![]() -
параметр положения распределения
-
параметр положения распределения
e - число Эйлера (2.71...)
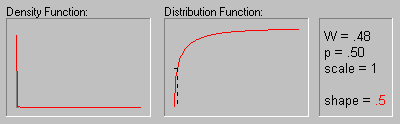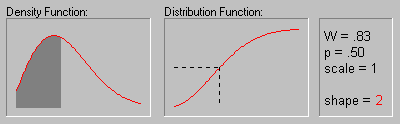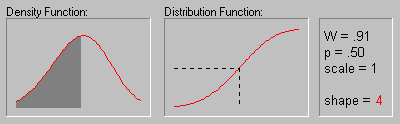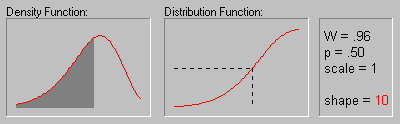
На рисунке показано изменение распределения
Вейбулла при увеличении параметра формы (.5, 1, 2, 3,
4, 5 и 10).
Распределение Коши. Распределение Коши (этот термин был впервые использован Успенским в 1937 г.) имеет следующую функцию плотности:
f(x) = 1/(![]()
![]() *{1 + [(x-
*{1 + [(x-![]() )/
)/![]() ]2})
]2})
0 < ![]()
где
![]() - параметр
положения (медиана)
- параметр
положения (медиана)
![]() - параметр
масштаба
- параметр
масштаба
![]() - число пи (3.1415...)
- число пи (3.1415...)
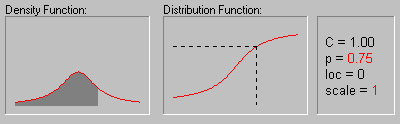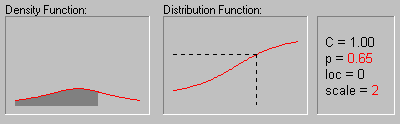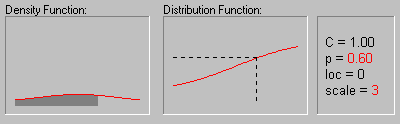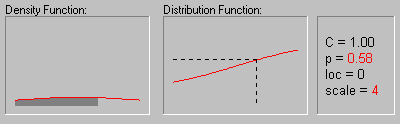
На рисунке показано изменение формы
распределения Коши в зависимости от
различных значений параметра масштаба (1, 2, 3 и 4)
при параметре положения равном 0 .
Распределение Лапласа. Распределение Лапласа (или двойное экспоненциальное) имеет следующую функцию плотности:
f(x) = 1/(2b)*e-|x-a|/b
-![]() < x <
< x < ![]()
где
a - среднее распределения
b - параметр масштаба
e - число Эйлера (2.71...)
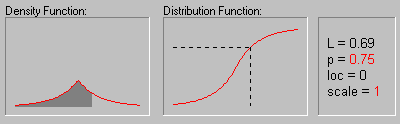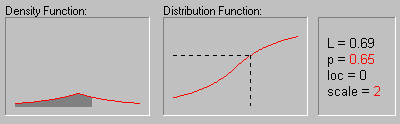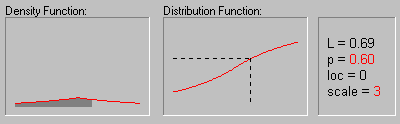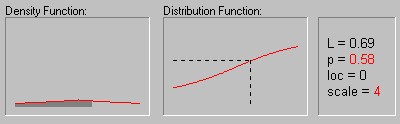
На рисунке показано изменение формы
распределения Лапласа в зависимости от значений
параметра масштаба (1, 2, 3 и 4) при нулевом значении
среднего.
Распределение Парето. Стандартное распределение Парето имеет следующую функцию плотности (для положительного параметра c ):
f(x) = c/xc+1 1 ![]() x, c > 0
x, c > 0
где
c параметр (формы)
распределения.
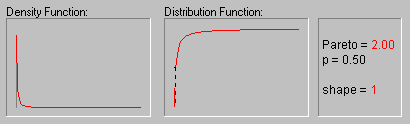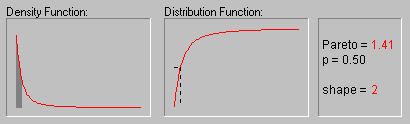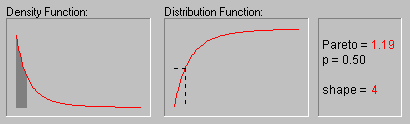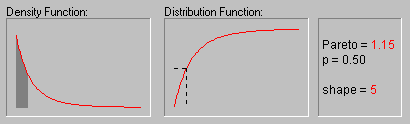
На рисунке показан вид распределения Парето
при различных значениях параметра (1, 2, 3, 4 и 5).
Распределение Пуассона. Распределение Пуассона (этот термин был впервые использован Сопером в 1914 г.) определяется следующим образом:
f(x) = (![]() x
* e-
x
* e-![]() )/x!
)/x!
for x = 0, 1, 2, .., 0 < ![]()
где
![]() - ожидаемое
значение x (среднее)
- ожидаемое
значение x (среднее)
e - число Эйлера (2.71...)
Распределение Релея. Распределение Релея имеет следующую функцию плотности:
f(x) = x/b2 * e-(x 2/2b2)
0 ![]() x <
x < ![]()
b > 0
где
b - параметр масштаба
e - число Эйлера (2.71...)
См. также Анализ процессов.
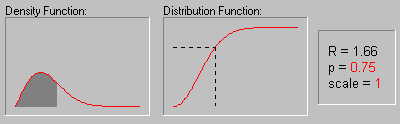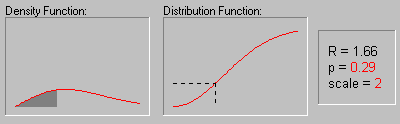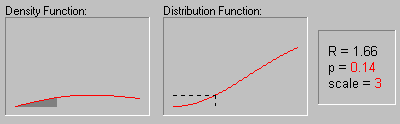
На рисунке показано изменение формы
распределения Релея в зависимости от значений
параметра масштаба (1, 2 и 3).
Распределение хи-квадрат. Распределение хи-квадрат определяется следующим образом:
f(x) = {1/[2![]() /2 *
/2 * ![]() (
(![]() /2)]} * [x(
/2)]} * [x(![]() /2)-1 * e-x/2]
/2)-1 * e-x/2]
![]() = 1, 2, ..., 0 < x
= 1, 2, ..., 0 < x
где
![]() - число
степеней свободы
- число
степеней свободы
e - число Эйлера (2.71...)
![]() -
гамма-функция
-
гамма-функция
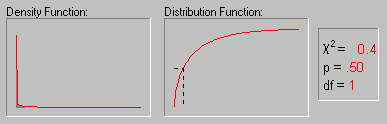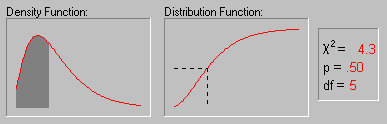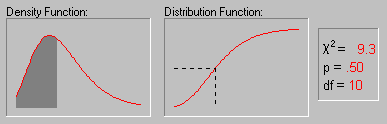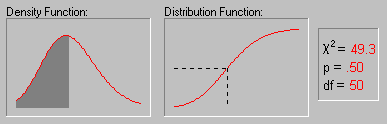
На рисунке показано изменение формы хи-квадрат
распределения при увеличении числа степеней
свободы (1, 2, 5, 10, 25 и 50).
Расстояние
городских кварталов (манхэттенское расстояние).
Это расстояние является просто средним
разностей по координатам. В большинстве случаев
эта мера расстояния приводит к таким же
результатам, как и для обычного расстояния
Евклида. Однако отметим, что для этой меры
влияние отдельных больших разностей (выбросов) уменьшается (так как
они не возводятся в квадрат). См. также раздел Кластерный анализ.
Расстояния Кука. Это еще одна мера влияния соответствующего наблюдения на уравнение регрессии. Эта величина показывает разницу между вычисленными B - коэффициентами и значениями, которые получились бы при исключении соответствующего наблюдения. В адекватной модели все расстояния Кука должны быть примерно одинаковыми; если это не так, то имеются основания считать, что соответствующее наблюдение (или наблюдения) смещает оценки коэффициентов регрессии.
См. также разделы Стандартизованные
остатки, Расстояния
Махаланобиса и Удаленные
остатки.
Расстояния Махаланобиса. Независимые переменные в уравнении регрессии можно представлять точками в многомерном пространстве (каждое наблюдение изображается точкой). В этом пространстве можно построить точку центра. Эта "средняя точка" в многомерном пространстве называется центроидом, т.е. центром тяжести. Расстояние Махаланобиса определяется как расстояние от наблюдаемой точки до центра тяжести в многомерном пространстве, определяемом коррелированными (неортогональными) независимыми переменными (если независимые переменные некоррелированы, расстояние Махаланобиса совпадает с обычным евклидовым расстоянием). Эта мера позволяет, в частности, определить является ли данное наблюдение выбросом по отношению к остальным значениям независимых переменных.
См. также разделы Стандартизованные
остатки, Удаленные
остатки и Расстояния Кука.
Расширение HTM. Это
расширение используется для обозначения файлов,
записанных в формате HTML.
Расширение JPG. Это
расширение используется для обозначения файлов,
записанных в формате JPEG.
Регрессионные B-коэффициенты. Линия в двумерном пространстве (задаваемом двумя переменными) определяется уравнением Y=a+b*X; или, подробнее: значение переменной Y может быть вычислено как сумма константы (a) и произведения углового коэффициента (b) на значение переменной X. Константу также часто называют свободным членом, а угловой коэффициент называют коэффициентом регрессии или B-коэффициентом. В общем случае, процедура множественной регрессии оценивает уравнение линейной регрессии в виде:
Y = a + b1*X1 + b2*X2 + ... +bp*Xp
Отметим, что в этом уравнении коэффициенты регрессии (или B коэффициенты) представляют независимые вклады каждой независимой переменной в зависимую переменную. Однако, их значения не сравнимы, поскольку зависят от единиц измерения и диапазонов измерения соответствующих переменных. Таблица результатов регрессионного анализа содержит как обычные регрессионные коэффициенты (B-коэффициенты), так и бета-коэффициенты (отметим, что коэффициенты бета являются сравнимыми для разных переменных).
См. также раздел Множественная
регрессия.
Регрессионные бета-коэффициенты. Коэффициенты бета являются коэффициентами, которые были бы получены, если бы мы заранее стандартизовали все переменные, т.е. сделали их среднее равным 0, а стандартное отклонение равное 1. Одно из преимуществ бета-коэффициентов (по сравнению с B коэффициентами) заключается в том, что бета-коэффициенты позволяют сравнить относительные вклады каждой независимой переменной в предсказание зависимой переменной.
См. также раздел Множественная
регрессия.
Регрессия. Категория задач, где цель состоит в том, чтобы оценить значение непрерывной выходной переменной по значениям входных переменных.
См. также раздел Множественная
регрессия.
Регуляризация (для нейронных сетей). Модификация алгоритмов обучения, имеющая цель предотвратить пере- и недо-подгонку на обучающих данных за счет введения штрафа за сложность сети (обычно штрафуются большие значения весов - они означают, что отображение, моделируемое сетью, имеет большую кривизну) (Bishop, 1995).
См. раздел Neural Networks.