Пакетные
алгоритмы программы Нейронные сети STATISTICA
(STATISTICA Neural Networks). Алгоритмы обучения,
вычисляющие усредненный градиент по всей эпохе
вместо того, чтобы производить коррекцию после
обработки каждого наблюдения. К этому типу
алгоритмов относятся методы быстрого
распространения, дельта-дельта с чертой, спуск
по сопряженным градиентам и метод
Левенберга-Маркара.
ПД (пропущенные
данные). То же, что и пропущенные
значения.
Перемешать данные
(для нейронных сетей). Случайное разбиение
наблюдений на обучающее и контрольное множества,
так чтобы они (насколько это возможно) получились
статистически несмещенными.См. раздел Нейронные сети.
Перемешать,
обратное распространение (для нейронных сетей).
Подача обучающих наблюдений на каждой эпохе в случайном порядке с
целью предотвратить различные нежелательные
эффекты, которые без этого приема могут иметь
место (например, осцилляции и сходимость к
локальным минимумам). См. раздел Нейронные сети.
Переобучение (для нейронных сетей). При итерационном обучении - чрезмерно точная подгонка, которая начинает иметь место, если алгоритм обучения работает слишком долго (а сеть слишком сложна для такой задачи или для имеющегося объема данных).
См. раздел Нейронные сети.
Пересекающиеся факторы. Некоторые экспериментальные (факторные) планы являются полностью пересекающимися, т.е. каждый уровень каждого фактора встречается на каждом уровне всех остальных факторов. Например в плане 2 (типа лекарств) x 2 (типа вирусов), каждый тип лекарства должен быть проверен на каждом типе вируса.
См. также раздел Дисперсионный
анализ.
Пиктографики. Одним из мощных средств разведочного анализа данных являются многомерные пиктографики. Главная идея пиктографиков состоит в представлении отдельных единиц наблюдения в виде определенных графических объектов; при этом значения переменных ставятся в соответствие определенным характеристикам или параметрам этих объектов (обычно одно наблюдение = одному объекту). Это соответствие таково, что общий вид объектов меняется как функция конфигурации значений. Таким образом, наблюдатель может идентифицировать уникальные для каждой конфигурации значений наглядные характеристики объектов. Исследование таких пиктограмм может помочь обнаружить определенные группы простых зависимостей и взаимосвязей между переменными.
См. раздел Графические
методы анализа: пиктографики.
Пиктографики - "Лица Чернова". "Лица Чернова" - это один из наиболее искусно разработанных типов пиктографиков. Для каждого наблюдения рисуется отдельное "лицо", где относительные значения выбранных переменных представлены как формы и размеры отдельных черт лица (например, длина носа, угол между бровями, ширина лица).
См. раздел Графические
методы анализа: пиктографики.
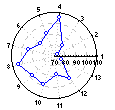
Пиктографики - Звезды. На пиктографике этого типа для каждого наблюдения рисуется своя пиктограмма в виде звезды; относительные значения выбранных переменных выражены относительными длинами отдельных лучей каждой звезды (по часовой стрелке, начиная с 12:00). Концы лучей соединены линиями.

См. раздел Графические
методы анализа: пиктографики.
Пиктографики - Круговые диаграммы. На пиктографике этого типа значения для каждого наблюдения представлены в виде круговых секторов (по часовой стрелке, начиная с 12:00); относительные значения выбранных переменных соответствуют площадям круговых секторов.

См. раздел Графические
методы анализа: пиктографики.
Пиктографики - Линии. На пиктографике этого типа для каждого наблюдения рисуется свой линейный график; относительные значения выбранных переменных для каждого наблюдения выражаются высотами соответствующих точек излома над уровнем линии основания.
См. раздел Графические
методы анализа: пиктографики.
Пиктографики - Лучи. На пиктографике этого типа для каждого наблюдения рисуется своя пиктограмма в виде солнца; каждый луч отображает одну из выбранных переменных (по часовой стрелке, начиная с 12:00), а длина луча равна относительному значению соответствующей переменной. Значения переменных для каждого наблюдения соединены линией.

См. раздел Графические
методы анализа: пиктографики.
Пиктографики - Многоугольники. На пиктографике этого типа для каждого наблюдения рисуется свой многоугольник; относительные значения выбранных переменных выражаются расстояниями от центра пиктограммы до соответствующих углов многоугольника (по часовой стрелке, начиная с 12:00).

См. раздел Графические
методы анализа: пиктографики.
Пиктографики - Профили. На пиктографике этого типа для каждого наблюдения рисуется своя область; относительные значения выбранных переменных для каждого наблюдения выражаются высотами соответствующих вершин контура над уровнем линии основания.
См. раздел Графические
методы анализа: пиктографики.
Пиктографики - Столбцы. На пиктографике этого типа для каждого наблюдения рисуется своя столбчатая диаграмма; относительные значения выбранных переменных для каждого наблюдения выражаются высотами соответствующих столбцов.
См. раздел Графические
методы анализа: пиктографики.
Планирование эксперимента (ПЭ, планирование промышленных экспериментов). В промышленных приложениях методы планирования эксперимента (ПЭ) используют технику дисперсионного анализа применительно к производству продукции. Основная цель заключается в получении максимального количества объективной информации относительно факторов, воздействующих на процесс производства, привлекая столь мало наблюдений (как правило дорогостоящих) насколько это возможно. В промышленных приложениях сложные взаимодействия многих факторов, влияющих на выпуск продукции, часто рассматриваются как "мешающие" (т.к. они не интересны и только усложняют процесс выделения важных факторов и в экспериментах со многими факторами их невозможно анализировать). Однако если вы просмотрите стандартные учебники по промышленным экспериментам (Box, Hunter, and Hunter, 1978; Box and Draper, 1987; Mason, Gunst, and Hess, 1989; Taguchi, 1987), то обнаружите, что в них прежде всего обсуждаются планы со многими факторами (например, 16 или 32), в которых взаимодействия эффектов оценить невозможно, и основное внимание сосредотачивается на том, как достоверно (несмещенно) оценить главный эффект (и возможно, взаимодействие второго порядка), используя минимальное число наблюдений.
Для получения дополнительной информации см.
главу Планирование
эксперимента.
Подавляющая переменная. Подавляющая переменная (при расчете множественной регрессии) имеет нулевую (или почти нулевую) корреляцию с критериальной переменной, но коррелирована с одной или несколькими предикторными переменными, и поэтому она подавляет не относящуюся к делу дисперсию независимых переменных. Например, вы пытаетесь предсказать временные результаты бегунов на 40- метровой дистанции. В качестве предикторов мы используем Рост и Вес бегуна. Теперь, предположим, что Рост не коррелирован с Временем, а Вес - коррелирован. Также предположим, что Вес и Рост коррелированы. Если Рост является подавляющей переменной, он подавляет, или управляет не относящейся к делу дисперсией (например, дисперсией, которую разделяют предикторы а не критериальная переменная), увеличивая тем самым частные корреляции. Это можно рассматривать как избавление от шума при изучении процесса.
Пусть t = Время, h = Рост, w = Вес, rth = 0.0, rtw = 0.5 и rhw = 0.6.
Вес в этом случае объясняет 25% (Rtw**2 = 0.5**2) изменчивости переменной Время. Однако, если включить в модель Рост, дополнительные 14% изменчивости Времени будут объяснены даже несмотря на то, что Рост не коррелирован с Временем:
Rt.hw**2 = 0.5**2/(1 - 0.6**2) = 0.39
Подробнее см. работу Pedhazur, 1982.
Подстановка среднего вместо пропущенных данных. Если выбрать метод подстановки среднего, то во время анализа пропущенные данные будут заменяться средними значениями соответствующей переменной.
См. также раздел Построчное
и попарное удаление пропущенных данных.
Полиномиальная подгонка. При выборе такого варианта аппроксимации к данным подгоняется полиномиальная функция следующего вида:
y = b0 + b1x + b2x2 + b3x3 + ... + bnxn
где n есть степень полинома.
Подгонка центрированных полиномиальных
моделей с помощью множественной
регрессии. Проведение подгонки полиномов
высших порядков от независимой переменной с
ненулевым средним может создать значительные
вычислительные трудности. А именно, эти полиномы
могут оказаться высоко коррелированными из-за
присутствия ненулевого среднего в независимой
переменной. При работе с большими числами
(например с датами в юлианской системе
летоисчисления), эта проблема становится
достаточно серьезной, и если не принять
соответствующие меры, может привести к неверным
результатам. Решение этой проблемы заключается в
центрировании независимой переменной (поэтому
иногда эту процедуру называют
"центрированными полиномами"), т.е.
вычитании среднего значения перед вычислением
полиномов. Примеры такого анализа смотрите в
классической работе Neter, Wasserman, & Kutner (1985, глава 9),
где содержится подробное обсуждение этой темы (и
анализа полиномиальных моделей в целом).
Положительная корреляция. Связь между двумя переменными может быть следующей - когда значения одной переменной возрастают, значения другой переменной также возрастают. Это и показывает положительный коэффициент корреляции. Про такие переменные говорят, что они положительно коррелированы.
См. также Корреляции -
Вводный обзор.
Полунормальные
вероятностные графики. Категоризованные
полунормальные вероятностные графики.
Этот график используется для оценки
нормальности распределения переменной, т.е.
близости этого распределения к нормальному.
Зависимость между выбранной переменной и
"ожидаемыми от нормального распределения"
значениями изображается на диаграмме рассеяния.
Полунормальный вероятностный график строится
тем же способом, что и стандартный
нормальный вероятностный график, с тем
отличием, что рассматривается только
положительная часть нормальной кривой. Таким
образом, по оси Y будут откладываться только
положительные нормальные значения. Этот график
удобно использовать в том случае, когда нужно
игнорировать знак остатков, т.е. когда
пользователя интересует только распределение их
абсолютных значений.
Полярные
координаты. В полярных координатах (r,![]() ) положение точки (на
плоскости) определяется расстоянием (r) до
нее от фиксированной точки на фиксированной
прямой (полярной оси) и углом (
) положение точки (на
плоскости) определяется расстоянием (r) до
нее от фиксированной точки на фиксированной
прямой (полярной оси) и углом (![]() , в радианах) между радиус-вектором
точки и этой фиксированной прямой.
, в радианах) между радиус-вектором
точки и этой фиксированной прямой.
Графики в полярных используются для
представления функций, а также зависимостей,
включающих переменную, отражающую направление.
См. также Декартовы
координаты.
Понижение
размерности. Сжатие данных путем
уменьшения их размерности (в разведочном
многомерном анализе). Такая интерпретация
термина "понижение размерности" характерна
для аналитических методов (главным образом
методов разведочного анализа многомерных
данных: факторного анализа,
многомерного
шкалирования, кластерного
анализа, канонической
корреляции, нейронных
сетей), предусматривающих уменьшение
размерности данных путем выделения нескольких
факторов, измерений, кластеров и т.п., которые
объясняют вариацию (многомерных) данных.
Дополнительно см. Сокращение
объема данных.
Попарное
удаление пропущенных данных. Если выбрано
попарное удаление пропущенных данных, то
наблюдения будут исключаться из вычислений
вместе с переменными, для которых в них
содержатся пропущенные данные. В случае
корреляций, корреляции между каждой парой
переменных вычисляются из наблюдений, которые
для этих переменных содержат допустимые
значения.
См. также разделы Попарное
удаление пропущенных данных и подстановка
среднего и Построчное
и попарное удаление пропущенных данных.
Попарное удаление пропущенных данных и подстановка среднего. Чтобы избежать потери данных при построчном удалении пропущенных данных, можно использовать один из двух следующих методов. Это (1) так называемая подстановка среднего пропущенных данных (замена всех пропущенных данных в переменной на среднее значение этой переменной) и (2) попарное удаление пропущенных данных. Эти методы обработки пропущенных данных используются во многих модулях; подстановку среднего можно также использовать для "удаления" пропущенных данных из набора данных. Подстановка среднего имеет как преимущества, так и недостатки по сравнению с попарным удалением. Основное его преимущество состоит в том, что в результате получается "внутренне целостный" набор результатов ("правильные" корреляционные матрицы). Основные недостатки:
Порог. Это
критическое значение (которое иногда выбирается
произвольно) используется для проверки
выполнения особых условий или условий
разделения точек. (В нейронных
сетях - это значение, которое вычитается из
взвешенной суммы в линейной PSP -функции для вычисления
уровня активации. Для радиальных элементов порог
интерпретируется как отклонение.)
Порядковая шкала. Порядковая шкала измерений позволяет ранжировать значения переменных. Измерения в порядковой шкале содержат информацию только о порядке следования величин, но не позволяют сказать "насколько одна величина больше другой", или "насколько она меньше другой".
См. также раздел Шкалы
измерений.
Послойное сжатие. Для построения послойно сжатого изображения сокращается основная область графика, чтобы справа и вверху освободить место для графиков на полях (и маленького графика в углу). Графики на полях представляют собой соответственно вертикально и горизонтально сжатые изображения основного графика.
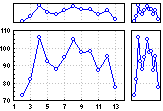
Дополнительно о послойном сжатии см. раздел Методы графического
анализа данных: послойное сжатие.
Постепенное устойчивое воздействие. В анализе временных рядов постоянное устойчивое воздействие приводит к постепенному устойчивому увеличению или уменьшению значений ряда после интервенции. Формула этого воздействия:
Воздействие t = ![]() * Воздействие t-1
+
* Воздействие t-1
+ ![]()
(для всехl t ![]() времени
воздействия, иначе = 0).
времени
воздействия, иначе = 0).
Это воздействие описывается двумя параметрами ![]() (дельта) и
(дельта) и ![]() (омега). Если
параметр
(омега). Если
параметр ![]() близок к 0 (нулю), то конечное воздействие
установится уже после нескольких наблюдений;
если же параметр
близок к 0 (нулю), то конечное воздействие
установится уже после нескольких наблюдений;
если же параметр ![]() близок к 1, то для проявления устойчивого
воздействия понадобится достаточно большое
количество наблюдений. Если
близок к 1, то для проявления устойчивого
воздействия понадобится достаточно большое
количество наблюдений. Если ![]() больше 0 и меньше 1 (границы
стабильности системы), воздействие будет
постепенным, a результат асимптотического
изменения (сдвига) среднего равен:
больше 0 и меньше 1 (границы
стабильности системы), воздействие будет
постепенным, a результат асимптотического
изменения (сдвига) среднего равен:
Асимптотическое изменение уровня = ![]() /(1-
/(1-![]() )
)
Построчное удаление пропущенных данных. Если выбрано построчное удаление пропущенных данных, то в анализ будут включаться только наблюдения, которые не содержат пропущенных данных ни для одной из выбранных переменных. При вычислении матрицы корреляций, все корреляции вычисляются с исключением наблюдений, которые содержат пропущенные данные для выбранных переменных (все корреляции основаны на одном и том же наборе данных).
См. также раздел Построчное
и попарное удаление пропущенных данных.
Пост-синаптическая потенциальная функция (PSP) функция. Функция, которая применяется к входным сигналам элемента, его весам и порогам и выдает уровень активации этого элемента. Наиболее часто используются линейные (взвешенная сумма входов минус порог) и радиальные (промасштабированный квадрат расстояния от вектора весов до входного вектора) PSP-функции.
См. Нейронные сети.
Правило остановки
(для деревьев классификации). Правило
остановки для дерева
классификации задает критерий, который
используется при определении "подходящего
размера" для дерева классификации, то есть
дерева классификации с нужным числом ветвлений и
оптимальной точностью прогноза. Процесс
нахождения дерева классификации "подходящего
размера" описан в разделе Вычислительные методы
в главе о деревьях классификации.
Предсказанные профили. При анализе результатов эксперимента наблюдаемые отклики на зависимые переменные можно подставить в уравнение предсказания, отдельное для каждой зависимой переменной (с разными коэффициентами, но одинаковыми слагаемыми). После построения уравнений можно вычислить предсказанные значения для зависимых переменных, для любой комбинации уровней предикторных переменных. Предсказанный профиль для зависимой переменной состоит из последовательности графиков (один график на каждую независимую переменную) предсказанных значений для зависимой переменной на разных уровнях одной предикторной переменной, при фиксированных значениях остальных независимых переменных. Изучение предсказанных профилей для зависимых переменных может показать, какие уровни предикторных переменных приводят к наиболее желательным предсказанным откликам на зависимые переменные.
Подробное описание построения предсказанных
профилей и профилей
желательности дано в разделе Профили предсказанных
откликов и желательность откликов.
Предсказывающее
отображение. Еще одним применением многомерного анализа
соответствий служит возможность
применения метода, эквивалентного методу множественной регрессии для
группирующих переменных, путем добавления
дополнительных точек-столбцов к бинарной
матрице (см. также матрицы Берта).
Например, предположим, что вы добавили к бинарной
матрице еще два столбца, чтобы ответить на вопрос
болел или нет опрашиваемый в течение прошедшего
года (т.е. вы добавляете столбец с названием Болен
и столбец с названием Не болен и, как обычно,
используете код 1 или 0 для обозначения
принадлежности к той или иной категории).
Применяя анализ соответствий для
рассматриваемой бинарной матрицы, во-первых, вы
можете объяснить влияние других показателей на
показатель заболеваемости с помощью качества представления (см. Анализ соответствий - Обзор),
и, во-вторых, отображение координат
дополнительных точек может указать природу
(направление) зависимостей между столбцами
бинарной матрицы и столбцами дополнительных
точек, отражающими заболеваемость. Этот метод
(добавление дополнительных точек в многомерный анализ
соответствий) иногда называют предсказывающим
отображением.
Присоединение сети.
Действие, позволяющее сделать из двух нейронных
сетей (совместимых по выходному и входному слоям)
одну составную сеть.
Программа AID. AID
(Automatic Interaction Detection) - программа методов
классификации, разработанная Morgan & Sonquist (1963), на
основе которой впоследствии были разработаны
пакеты методов деревьев классификации THAID (Morgan & Messenger, 1973) и CHAID (Kass, 1980). Все эти программы при
построении деревьев
классификации осуществляют многоуровневые
ветвления. Об отличиях методов, использованных в
этих пакетах, от алгоритмов, применяемых в других
программах построения деревья классификации, см.
раздел Сравнение с
другими пакетами, в которых реализован метод
деревьев классификации.
Программа CART. CART
- программа, реализующая методы деревьев классификации,
разработанная Breiman et. al. (1984). Подробнее о пакете CART,
см. раздел Вычислительные
методы в главе о деревьях классификации.
Программа CHAID. CHAID
- программа, реализующая методы деревьев
классификации, разработанная Kass (1980). В ней при
построении деревьев
классификации производятся многоуровневые
ветвления. Об отличиях методов пакета CHAID от
алгоритмов, применяемых в других программах
построения деревья классификации, см. раздел Сравнение с другими
пакетами, в которых реализован метод деревьев
классификации.
Программа FACT. FACT
- программа, реализующая методы деревьев классификации,
разработанная Loh and Vanichestakul (1988) и послужившая
предшественником пакета QUEST. Об
отличиях методов пакета FACT от алгоритмов,
применяемых в других программах построения
деревья классификации, см. раздел Сравнение с другими
пакетами, в которых реализован метод деревьев
классификации.
Программа QUEST. QUEST
- программа, реализующая методы деревьев классификации,
разработанная Loh and Shih (1997). Подробнее об отличиях
пакета QUEST от других программ построения
деревья классификации см. раздел Сравнение с другими
пакетами, в которых реализован метод деревьев
классификации.
Программа THAID. THAID
- программа, реализующая методы деревьев
классификации, разработанная Morgan & Messenger (1973). В
ней при построении деревьев
классификации производятся многоуровневые
ветвления. Об отличиях методов пакета THAID от
других программ построения деревья
классификации см. раздел Сравнение с другими
пакетами, в которых реализован метод деревьев
классификации.
Программное
обеспечение на производстве. Для
вычислительных систем, работающих на
промышленном производстве, таких, например, как
большие корпоративные компьютерные системы,
разрабатывается специальное программное
обеспечение. Эти приложения, как правило,
поддерживают возможности группового
доступа к системе, а также совместимы с
корпоративными хранилищами
данных. Подробнее о программном обеспечении
для предприятий, разработанном компанией StatSoft,
см. раздел STATISTICA
Enterprise-Wide Systems - Промышленные системы.
Промежуточные
(скрытые) слои (для нейронных сетей). Все
слои нейронной сети,
кроме входного и выходного; придают сети
способность моделировать нелинейные явления.
Пропущенные
значения. Неизвестные значения переменных
из файла данных. Несмотря на то, что наблюдения с
пропущенными значениями являются неполными, они
все-таки могут оказаться полезными при анализе
данных. Существуют различные методы замены
пропущенных данных (например, замена на среднее
значение, а также разные варианты интерполяции и экстраполяции). Может быть
также применено попарное удаление пропущенных
данных. См. разделы Попарное
удаление ПД, Построчное
удаление ПД, Попарное
удаление ПД или подстановка среднего значения
и Построчное или
попарное удаление пропущенных данных.
Пространственные графики. Этот график является особым способом представления данных 3М диаграммы рассеяния при помощи плоскости XY, расположенной на выбранном пользователем уровне вертикальной оси Z (которая проходит через центр плоскости).
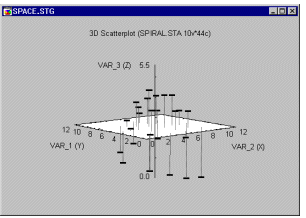
Пространственный график упрощает исследование некоторых трехмерных наборов данных. В этом случае рекомендуется таким образом ставить в соответствие переменные пространственным осям, чтобы по оси Z была расположена та из них, которая характеризует разные структурные зависимости двух других переменных.
См. также раздел Вращение
данных (в трехмерном пространстве) в главе Графические методы.
Профили желательности. Зависимость между предсказанными откликами для одной или более зависимых переменных и желательностью откликов называется функцией желательности. Построение профилей желательности включает задание функции желательности для каждой зависимой переменной приписыванием предсказанным значениям меток от 0 (очень нежелательно) до 1 (очень желательно). Индивидуальные значения желательности для предсказанных значений каждой зависимой переменной далее объединяются с помощью вычисления их геометрического среднего. Профили желательности состоят из последовательности графиков - один график для каждой независимой переменной, на фиксированных уровнях других независимых переменных. Исследование профилей желательности может показать какие уровни предикторных переменных дают наиболее желаемые отклики зависимых переменных.
Подробное описание построения профилей
откликов/желательности дано в разделе Профили предсказанных
откликов и желательность откликов.
Процентили. Процентиль распределения (этот термин был впервые использован Галтоном в 1885 г.) - это такое число xp, что значения p-й части совокупности меньше или равны xp. Например, 25-я процентиль (также называемая квантилью .25 или нижней квартилью) переменной - это такое значение (xp), что 25% (p) значений переменной попадают ниже этого значения.
Аналогичным образом вычисляется 75-я процентиль
(также называемая квантилью
.75 или верхней квартилью) -
такое значение, ниже которого попадают 75%
значений переменной.
Прямой
передачи сети. Нейронные
сети с различной структурой слоев, в которых
все соединения ведут только в сторону от входов к
выходам. Иногда используется как синоним для многослойных
персептронов.
Псевдокомпоненты. Псевдокомпоненты - это преобразованные значения компонент (построенных на тернарных графиках), для них:
x'i = (xi-Li)/(Total-L)
Здесь x'i обозначает i-ю псевдокомпоненту, xi - значение исходной компоненты, Li - нижний предел i-й компоненты, L - сумма всех нижних пределов всех компонент плана, Total - общая сумма. Это преобразование позволяет сравнить коэффициенты для различных факторов.
(См. Cornell, 1993, глава 3).
Псевдо-обратных
метод. Эффективный алгоритм оптимизации линейных моделей; известен
также под названием "сингулярное разложение
матрицы" (Bishop, 1995; Press et. al., 1992; Golub and Kahan, 1965).